
1. 책 DB를 넣어주세요.

2. 나의 스터디 흔적을 사진으로 보여주세요.

3. 이번 스터디에서 특별히 좋았던 점이나 어려웠던 점이 있었나요? 새로 알게된 부분이 있다면 알려주세요.
1) 숫자
숫자 표현법
|
숫자 표기
|
의미
|
|
4.24e10
|
4.24 * 10^10
|
|
0o숫자
|
8진수
|
|
0x숫자
|
16진수
|
연산자
|
연산자
|
의미
|
|
a ** b
|
a의 b제곱
|
|
a / b
|
a를 b로 나눈 값
|
|
a % b
|
a를 b로 나눈 나머지
|
|
a // b
|
a를 b로 나눈 몫
|
2) 문자열
문자열을 표기하는 방법
|
문자열 표기법
|
사용하는 시기
|
|
"ABCD"
|
작은 따옴표(')를 문자열에 포함시키고 싶을 때 사용
|
|
'ABCD'
|
큰 따옴표(")를 문자열에 포함시키고 싶을 때 사용
|
|
"""ABCD"""
|
여러 줄인 문자열을 표현하고 싶을 때
|
|
'''ABCD'''
|
문자열 연산
|
예시 코드
|
결과
|
설명
|
|
'A' + 'B'
|
'AB'
|
두 문자열을 연결
|
|
'A' * 3
|
'AAA'
|
문자열을 해당 숫자만큼 반복
|
|
len('Life is too short')
|
17
|
문자열의 길이 반환
|
문자열 인덱싱 / 슬라이싱
|
a = "Life is too short, You need Python"
|
|||
|
코드
|
결과
|
설명
|
|
|
a[3]
|
'e'
|
4번째 문자 반환
|
|
|
a[-1]
|
'n'
|
뒤에서 1번째 문자 반환
|
|
|
a[0]
|
'L'
|
1번째 문자 반환
|
|
|
a[0:4]
|
'Life'
|
인덱스 0 ~ 3 사이의 문자열 반환
|
|
|
a[5:7]
|
'is'
|
인덱스 5 ~ 6 사이 문자열 반환
|
|
|
a[19:]
|
'You need Python'
|
인덱스 19부터 끝까지의 문자열 반환
|
|
|
a[:17]
|
Life is too short
|
인덱스 처음부터 16까지의 문자열 반환
|
|
문자열 포매팅
|
코드
|
결과
|
|
"I eat %d apples." % 3
|
'I eat 3 apples'
|
|
num1 = 3
num2 = 4
"I eat %d apples and %d bananas" % (num1, num2)
|
'I eat 3 apples and 4 bananas'
|
|
"I eat {0} apples".format(3)
|
'I eat 3 apples'
|
|
num1 = 3
num2 = 4
"I eat {0} apples and {1} bananas".format(num1, num2)
|
'I eat 3 apples and 4 bananas'
|
|
"I eat {num1} apples and {num2} bananas".format(num1 = 3, num2 = 4)
|
'I eat 3 apples and 4 bananas'
|
|
코드
|
결과
|
|
|
왼쪽 정렬
|
"{0:<6}".format('hi')
|
'hi '
|
|
오른쪽 정렬
|
"{0:>6}".format('hi')
|
' hi'
|
|
가운데 정렬
|
"{0:^6}".format('hi')
|
' hi '
|
|
공백 채우기
|
"{0:=^6}".format('hi')
|
'==hi=='
|
|
소수점 표현하기(1)
|
"{0:0.4f}".format(3.42134234)
|
'3.4213'
|
|
소수점 표현하기(2)
|
"{0:10.4f}".format(3.42134234)
|
' 3.4213'
|
|
{, } 표현하기
|
"{{ }}".format()
|
'{ }'
|
f 문자열 포매팅 (파이썬 3.6 부터 사용 가능)
|
코드
|
결과
|
|
|
기본 사용법
|
name = 홍길동
age = 30
f'이름은 {name}, 나이는 {age}입니다.'
|
'이름은 홍길동, 나이는 30입니다.'
|
|
name = 홍길동
age = 29
f'이름은 {name}, 나이는 {age + 1}입니다.'
|
'이름은 홍길동, 나이는 30입니다.'
|
|
|
딕셔너리
|
d = {'name':'홍길동', 'age':30}
f'이름은 {d["name"]}, 나이는 {d["age"]}입니다.'
|
'이름은 홍길동, 나이는 30입니다.'
|
|
왼쪽 정렬
|
f'{"hi":<6}'
|
'hi '
|
문자열 관련 함수
|
기능
|
함수
|
비고
|
|
문자 개수 세기
|
count()
|
|
|
위치 알려주기
|
find()
|
찾는 문자가 존재하지 않으면 -1 반환
|
|
index()
|
찾는 문자가 존재하지 않으면 오류 발생
|
|
|
문자열 삽입
|
join()
|
|
|
소문자 → 대문자 바꾸기
|
upper()
|
|
|
대문자 → 소문자 바꾸기
|
lower()
|
|
|
왼쪽 공백 지우기
|
lstrip()
|
|
|
오른쪽 공백 지우기
|
rstrip()
|
|
|
양쪽 공백 지우기
|
strip()
|
|
|
문자열 바꾸기
|
replace()
|
|
|
문자열 나누기
|
split()
|
3) 리스트
리스트 인덱싱
|
a = [1, 2, ['a', 'b']]
|
|
|
코드
|
결과
|
|
a
|
[1, 2, ['a', 'b']]
|
|
a[0]
|
1
|
|
a[-1]
|
['a', 'b']
|
|
a[-1][0]
|
'a'
|
리스트 슬라이싱
(문자열 슬라이싱과 사용법이 동일하다)
|
a = [1, 2, 3, 4, 5]
|
|
|
코드
|
결과
|
|
a[0:2]
|
[1, 2]
|
리스트 연산
|
연산자
|
예시 코드
|
결과
|
설명
|
|
+
|
a = [1, 2, 3]
b = [4, 5, 6]
a + b
|
[1, 2, 3, 4, 5, 6]
|
'+'연산은 두 리스트를 단순히 이은 새 리스트를 생성한다.
|
|
*
|
a = [1, 2, 3]
a * 3
|
[1, 2, 3, 1, 2, 3, 1, 2, 3]
|
'*'연산은 그 횟수만큼 리스트를 반복하여 새로운 리스트를 생성한다.
|
|
len
|
a = [1, 2, 3]
len(a)
|
3
|
리스트에 있는 원소 개수를 반환한다.
|
리스트의 수정 / 삭제
|
|
코드
|
결과
|
|
리스트 수정
|
a = [1, 2, 3]
a[2] = 4
a
|
[1, 2, 4]
|
|
리스트 삭제
|
a = [1, 2, 3, 4, 5]
del a[2:]
a
|
[1, 2]
|
리스트 관련 함수
|
함수
|
설명
|
|
a.append(x)
|
리스트의 맨 마지막에 요소 x를 추가
|
|
a.sort()
|
정렬
|
|
a.reverse()
|
역순으로 뒤집기
|
|
a.index(x)
|
x 위치에 있는 값을 반환
|
|
a.insert(x, y)
|
x 위치에 요소 y를 삽입
|
|
a.remove(x)
|
처음으로 나오는 요소 x를 삭제
|
|
a.pop(x)
|
리스트의 x번째 요소를 반환하고 삭제 (x자리에 아무것도 안쓰면 맨 마지막 요소)
|
|
a.count(x)
|
리스트에 요소 x가 몇 개 있는지 조사하여 그 개수를 반환
|
|
a.extend(x)
|
원래의 a 리스트에 x 리스트를 더하기 (x 자리에는 리스트만 올 수 있다)
|
리스트 복사
4) 튜플
- 튜플과 리스트는 거의 동일하지만 다음과 같은 차이점이 있다.
1) 리스트는 []로 둘러싸고, 튜플은 ()로 둘러싼다.
2) 리스트는 값의 생성, 삭제, 수정이 가능하고 튜플은 값을 바꿀 수 없다.
- 튜플은 값이 항상 변하지 않길 바랄 때 사용한다.
- 실제 프로그램에서는 값이 변경될 때가 많기 때문에 리스트를 더 많이 사용한다.
5) 딕셔너리
- 연관 배열(Associative array), 해시(Hash)와 같은 개념이다.
- 기본 형태 : {Key1:Value1, Key2:Value2, Key3:Value3, ...}
- Key값의 조건
1) Key에는 변하지 않는 값을, Value는 변할 수 있는 값을 사용한다.
2) Key값은 고유한 값이어야 한다. 즉 중복되면 안된다.
3) Key값으로 리스트, 딕셔너리 등은 올 수 없지만 튜플은 올 수 있다.
딕셔너리 요소 추가 / 삭제
|
코드
|
결과
|
|
|
딕셔너리 요소 추가
|
a = {1:'a'}
a['name'] = 'pey'
a
|
{1:'a', 'name:'pey'}
|
|
딕셔너리 요소 삭제
|
a = {'A':1, 'B':2}
del a['A']
a
|
{'B':2}
|
딕셔너리 관련 함수
|
함수
|
설명
|
|
a.keys()
|
딕셔너리 a에 있는 key값들을 가지고 dict_keys 객체를 생성한다. 다만 리스트 고유의 함수를 수행할 수는 없으므로, 완전히 리스트로 변환하려면 'list(a.keys())'라고 써야한다.
|
|
a.values()
|
딕셔너리 a에 있는 value값들을 가지고 dict_values 객체를 생성한다.
|
|
a.items()
|
딕셔너리 a에 있는 key값들과 value값들의 쌍을 튜플로 묶은 후 dict_items 객체를 생성한다.
|
|
a.clear()
|
모든 요소를 삭제한다.
|
|
a.get('key값')
|
key값에 대응되는 value를 돌려준다.
a['key값'] 과의 차이점은, 존재하지 않는 key 값을 검색할 경우 오류를 발생시키지 않고 None을 돌려준다.
key 값이 없을 경우 None 말고 다른 디폴트 값을 반환받고 싶다면 a.get(x, '디폴트 값') 으로 쓸 수 있다.
|
|
'key값' in a
|
해당 key값이 딕셔너리에 존재하는지 조사한다.
있으면 True, 없으면 False를 반환한다.
|
6) 집합
- set()의 괄호 안에 리스트 / 문자열을 입력하여 집합을 생성한다.
- 집합(set)의 가장 큰 특징
1) 중복을 허용하지 않는다.
2) 순서가 없다.
- 집합은 중복을 허용하지 않기 때문에, 중복을 제거하기 위한 필터 역할로 종종 사용한다.
- 순서가 없는 자료형이기 때문에 인덱싱을 지원하지 않는다. (이는 딕셔너리도 마찬가지이다.)
- set에 저장된 값을 인덱싱으로 접근하려면 리스트나 튜플로 변환한 후 해야한다.
교집합 / 합집합 / 차집합
|
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9)]
|
||
|
코드
|
결과
|
|
|
교집합
|
s1 & s2
|
{4, 5, 6}
|
|
합집합
|
s1 | s2
|
{1, 2, 3, 4, 5, 6, 7, 8, 9}
|
|
차집합
|
s1 - s2
|
{1, 2, 3}
|
집합 관련 함수
|
함수
|
설명
|
|
s.add(x)
|
값 1개를 추가
|
|
s.update([x1, x2, x3])
|
값 여러 개를 추가
|
|
s.remove(x)
|
갑 x를 삭제
|
7) 불
- True와 False를 나타내는 자료형
- True와 False는 파이썬의 예약어로, 첫 문자를 항상 대문자로 써야한다.
- 자료형에도 참과 거짓이 있다.
1) 문자열, 리스트, 튜플, 딕셔너리 → 값이 비어있으면 False
2) 숫자 → 0이면 False
3) None → False
- 불 연산 bool() : 괄호 안의 값이 참인지 판단한 후, True/False 값을 반환하는 내장함수이다.
- a is b : a와 b가 가리키는 객체(메모리 주소)가 동일한지 판단한 후, True/False 값을 반환한다.
* str() 함수 : 숫자를 문자열 형태로 바꿔주는 파이썬 내장 함수
* id() 함수 : 객체의 주소 값을 반환해주는 파이썬 내장 함수
* 객체 : 파이썬에서 사용되는 모든 자료형
* 두 변수에 담긴 값을 바꾸는 방법 : a, b = b, a
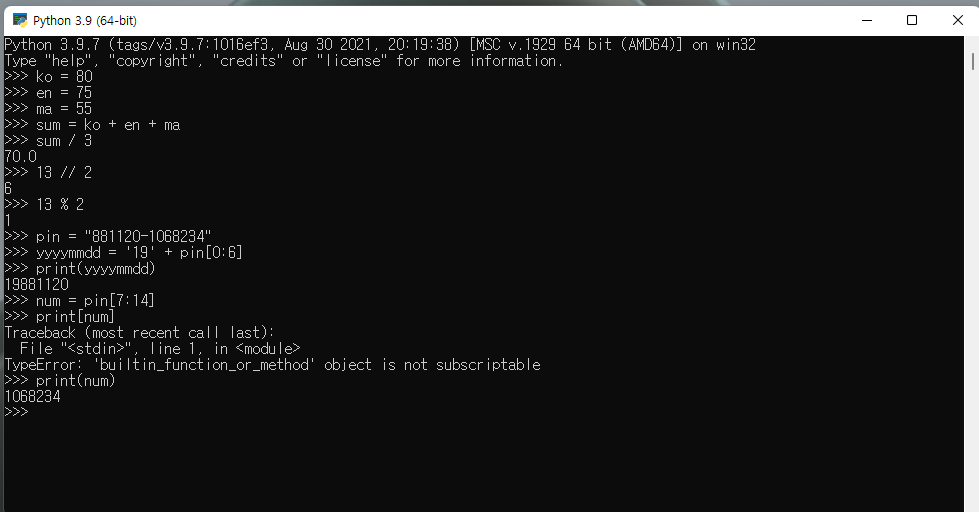
4. 열심히 실습한 코드를 저장해 첨부해 주시거나 자랑할만한 스크린샷이 있다면 올려주세요.
'etc. > Do it! 공부단' 카테고리의 다른 글
| Do it! 점프 투 파이썬 / 04단원 프로그램의 입력과 출력은 어떻게 해야 할까? (0) | 2022.04.18 |
|---|---|
| Do it! 점프 투 파이썬 / 03단원 프로그램의 구조를 쌓는다! 제어문 (0) | 2022.04.17 |
| Do it! 점프 투 파이썬 / 01단원 파이썬이란 무엇인가? (0) | 2022.04.11 |
| Do it! 자바스크립트 입문 / 10단원 웹 브라우저를 다루는 방법, 브라우저 객체 모델 (0) | 2022.04.05 |
| Do it! 자바스크립트 입문 / 09단원 폼과 자바스크립트 (0) | 2022.04.05 |