
https://www.youtube.com/watch?v=YACC1t_oSlA
※ 영상을 보며 아래 노션 페이지에 내용을 정리하였고, 포스트에는 노션을 한 번 더 요약한 내용을 담았습니다.
[우아콘2023] Kafka Streams를 활용한 이벤트 스트림 처리 삽질기 | Notion
https://www.youtube.com/watch?v=YACC1t_oSlA
jn307742.notion.site
내용 요약
스트림 처리 도입 배경
과거의 '지역별 배달/라이더 현황' 집계 방법
과거에는 대량의 데이터를 주기적으로 처리하는 방식인 배치 처리로 하고 있었으나, 다음 4가지 이유로 실시간으로 데이터를 처리하는 스트림 처리로의 전환이 필요로해졌다. 일 수백만 건 주문 건수, 데이터의 양이 늘었다.
- 주문 건수 및 데이터의 양의 증가
- 요구사항 증가로 인해 점점 복잡해지는 처리 로직
- 주문 수 편차로 인해 예측이 어려운 처리시간
- 배치 주기에 따라 자꾸 한발 느린 이상 탐지
Kafka Streams를 선택한 이유

유명한 스트림 처리 프레임워크에는 Apache Flink와 Kafka Streams 등이 있다.
Kafka Streams는 지원하는 서드파티가 Kafka 밖에 없고, 국내 사례가 부족하다는 단점이 있었지만, 별도 클러스터 구성이 필요 없다는 장점이 있어 선택하게 되었다.
Kafka Streams 기본 개념

Kafka의 데이터는 Kafka Streams의 스트림 프로세서로 흘러들어가게 된다. 즉 스트림 프로세서는 Kafka의 컨슈머로서, 토픽으로 들어온 데이터를 분산해서 처리한다.
처리를 하면서 필요한 상태 관리는 상태 저장소라는 로컬 저장소를 활용하였다.
배달 타입별로 배달을 집계하는 상황을 예로 들어보자.
- 스트림 프로세서는 '배달'이라는 토픽을 스트림으로 input 받는다.
- 스트림 프로세서는 데이터를 처리하고, 그 결과를 상태 저장소라는 분산 저장소에 저장한다.
- 이 결과를 별도의 토픽으로 흘려서 외부에 활용할 수도 있다.
Kafka Streams에서의 프로그래밍 방법
1. DSL (Domain Specific Language) 프로그래밍 방식

자주 사용하는 기능들은 이미 메서드로 만들어놓고, 이를 활용하는 프로그래밍 방식이다.
필터링, 그룹핑, 카운팅과 같은 기능을 위 그림과 같이 작성할 수 있다.
2. Processor API

좀 더 고도화된 기능이나 세밀한 작업이 필요한 경우 사용하는 방식이다.
low 레벨 프로그래밍이 가능한 방식이다.
도메인 요구사항과 전략
도메인 요구사항
1. 배달 이벤트와 라이더 이벤트를 통해 특정 라이더의 상황을 파악할 수 있어야한다.
→ ”OOO 라이더는 역삼동에서 배달 수행 중이군!”
2. 행정동 규모의 세분화된 지역별 현황을 집계할 수 있어야한다.
→ ”역삼동에서 배달을 수행 중인 라이더는 300명이군!”
3. 언제 어디서나 데이터 제공을 보장해야한다.
요구사항 1. 전처리

라이더 이벤트에는 라이더의 위치 정보가 포함되는데, 이 정보는 gps 좌표이다. 따라서 이 gps 좌표를 행정동으로 변환하는 전처리 과정이 필요했다. 따라서 라이더 이벤트를 구독해서 gps 좌표를 행정동으로 변환한 뒤에, 새로운 이벤트를 발행하는 형태로 전처리를 하고 있다.
이렇게 발행한 확장된 라이더 스트림과 배달 스트림을 적절히 조인 함으로써 라이더 스냅샷 스트림을 만들수 있다.
데이터를 집계하는 입장에서는 스냅샷 정보가 필요하다. 라이더 스냅샷 정보는 해당 라이더가 어느 행정동에 속해있는지 배달을 수행 중인지 여부를 포함한다.
요구사항 2. 지역별 데이터 집계
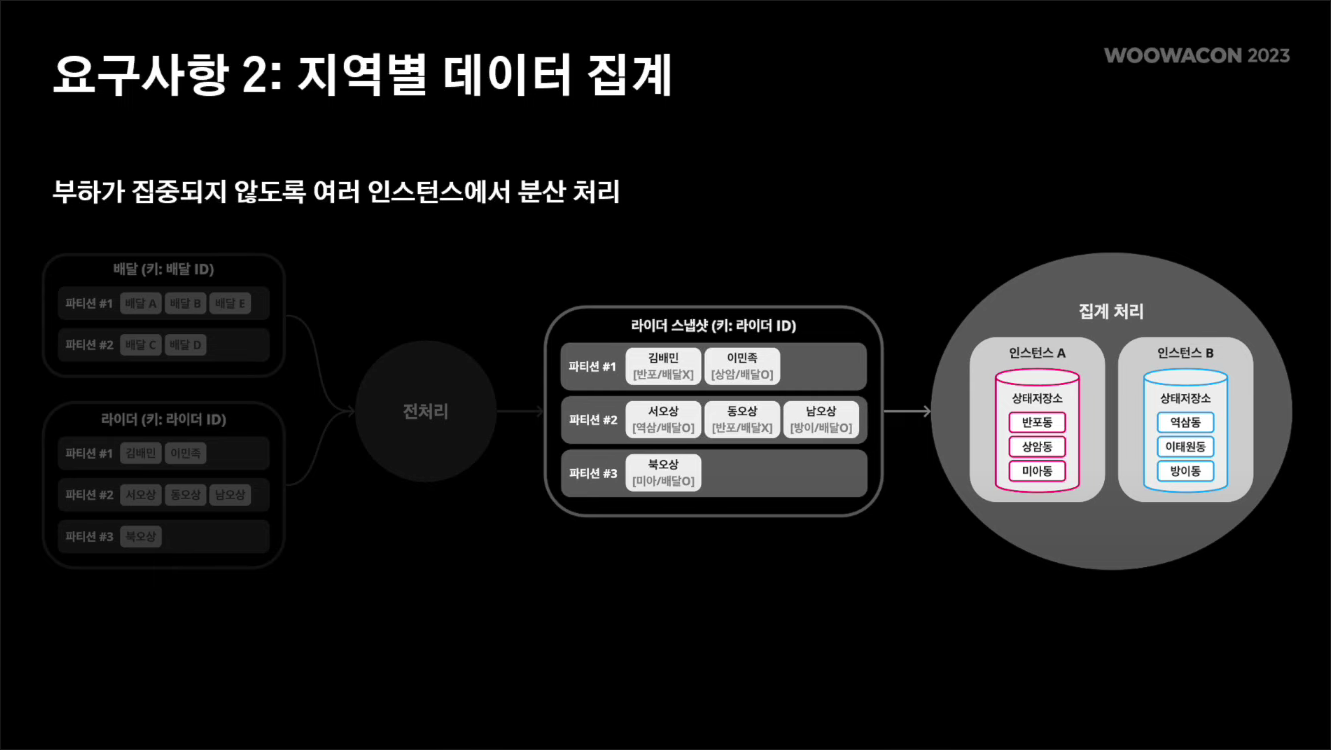
어떤 하나의 인스턴스에서 데이터가 처리되면 부하가 집중되기 때문에, 여러 인스턴스에서 분산돼서 처리시켜야한다. 카프카 스트림즈를 사용하면 분산 처리를 할 수 있다.
앞서 만들어놓은 라이더 스냅샷 스트림을 받아들여서 카프카 스트림즈를 통해 집계 연산을 수행한다.
행정동 단위로 그룹핑을 하고 카운팅과 같은 집계 연산을 수행할 수 있다. 연산 결과는 역시 행정동 단위로 상태 저장소에 저장될 것이며, 이 데이터는 분산 저장된다.
예를 들어 반포동이라는 지역에 대한 결과값은 인스턴스 a에 저장되고, 역삼동은 인스턴스 b에 저장될 수 있다.
요구사항 3. 데이터 조회

이렇게 저장된 상태저장소의 데이터를 조회할 수 있다.
데이터 조회 요청은 로드밸런서를 타고 들어온다. 만일 1.데이터가 있는 인스턴스로 요청이 들어온 경우, 해당 인스턴스에서 상태저장소를 조회해서 결과를 직접 제공할 수 있다.
2.데이터가 없는 인스턴스로 요청이 들어온 경우에도 문제가 되지 않는다. 카프카 스트림즈의 경우에는 메타 데이터를 관리하고 있기 때문에, 어떤 데이터가 어느 인스턴스에 속해 있는지를 알고 있다. 그래서 데이터를 갖고 있는 인스턴스에게 도움을 받아서 결과를 제공할 수 있다.

만약 3.상태저장소에 접근할 수 없는 경우가 있다면 어떤 경우일까?
상태저장소는 논리적으로 스트림 프로세서 내부에 위치하게 된다. 그렇기 때문에 스트림 프로세서가 정상이 아닌 경우에는 상태 저장소에 접근할 수 없다. 시스템 장애 뿐만 아니라 시스템을 배포하는 순간이라던지, 스케일 인/아웃이 이루어지는 시점이 상태저장소에 접근할 수 없는 시점이다.

이러한 시점에도 데이터를 제공해야되기 때문에, 백업 저장소를 구축하게 되었다.
집계 결과를 일반적으로 상태 저장소에 저장하고, 그 결과를 다시 새로운 토픽으로 발행한다. 이 토픽을 구독해서 별도의 백업 저장소를 구축하고 있다. 이 백업 저장소는 데이터를 분산해서 저장할 필요는 없고, 그냥 하나의 백업저장소에 모든 지역 정보를 저장하고 있다.
전체 구조

이슈와 해결방안
이슈 1. 과도한 토픽 파티션 수
주의할 점
- 토픽의 파티션 수는 한 번 늘리면 줄일 수 없다.
- 파티션은 브로커의 파일 시스템 리소스를 사용하기 때문에, 매우 큰 수의 파티션은 클러스터 전체 성능에 영향을 줄 수 있다.
- 내부 토픽의 파티션 수는 원본 토픽의 파티션 수를 따른다.
방안
- 일단 적은 수로 시작하고 운영하며 점점 늘려가자.
- 파티션 조정을 위한 중간(bypass) 토픽을 만드는 것을 검토하자.
- 처리속도가 느리다고 파티션 수 증설에 의존하지 말자.
이슈 2. 토픽의 단위
문제 상황
맨 처음에는 하나의 General한 토픽(ex. delivery-eventstore)에 모든 데이터를 발행했다.
→ 자연스레 시스템과 트래픽의 확장에 따라, 메시지 양이 많아지고 파티션도 점점 많이 필요하게 되었다.
→ 컨슈머는 관심있는 데이터 외에 너무 많은 메시지를 수신받고 필터링하게 되었다.
Root Cause
잘못 작성된 코드로 인한 컨슈머 그룹 내 너무 많은 멤버 수
- 과한 동시성 부여 Concurrency(num.stream.threads) = 32
- 10개의 서로 다른 스트림 프로세서가 동일한 id 값으로 설정됨 (application.id)
- Spring 인스턴스 수 : 8
- 총 멤버 수 : 32 * 10 * 8 = 2560
해결
- 토픽을 구분하는 단위 : 정답은 없지만 도메인 단위로 구분하고 있다. (ex. 주문, 배달, 라이더 등)
- 파티션 72개로 처리하던 트래픽을, 현재는 도메인 단위로 토픽을 나누고 18개의 파티션만으로 충분히 처리하고 있다.
이슈 3. 과도한 LAG 쌓임
문제 상황
서버 배포 시 리밸런싱이 발생하는데, 이때 특정 스트림 프로세서에 Lag이 과도하게 쌓인다.
Lag이란?
- 토픽의 최신 메시지와 컨슈머가 처리한 메시지의 위치 차이
- 컨슈머가 아직 처리하지 못하고 쌓인 메시지 양
- 밀린 숙제의 양이라고 생각하면 쉽다.
Lag이 너무 많이 쌓이면 이벤트 딜레이가 발생할 수 있다.

해결 방안
- 쓰레드(컨슈머)의 양을 늘려서 해결한다.
- 단, 쓰레드가 너무 많으면 쉬는 쓰레드가 생기기 때문에 적절한 양을 설정해야한다.
- 권장 : 파티션 수 = 인스턴스 수 x 쓰레드 수 (num.stream.threads)
이슈 4. 잦은 리밸런싱, 오랜 리밸런싱

리밸런싱이란?
컨슈머 그룹 내 컨슈머들에게 작업을 균등하게 분배하기 위해, 파티션 할당을 조정하는 동작
리밸런싱 발생 시점
- 파티션 할당 조정이 필요한 경우
- 대표적으로 토픽 파티션 수 증설 / 서버 스케일링 / 컨슈머 이슈로 탈락할 때 등
리밸런생 동안 조정되는 컨슈머의 처리가 중단되므로, 최대한 불필요한 리밸런싱의 횟수와 소요시간을 줄여야한다.
리밸런싱 전략
- Eager : “모든” 컨슈머의 파티션 할당을 끊고 재조정한다. 때문에 일시적으로 모든 메시지 처리가 막히는 단점이 있다.
- Cooperative : 모든 매핑을 취소하지 않고, 여러 번에 걸쳐 조정해 나간다. 이를 통해 보다 안정적인 메시지 처리 환경을 유지한다.
리밸런싱 시간/횟수 줄이는 방법
- 검토해 볼 만한 설정 옵션
- 리밸런싱 전략을 eager 대신 cooperative 쓰기
- 컨슈머 처리속도/처리량 조절을 위한 레코드 플립 주기/양 (max.poll.interval.ms / max.poll.records)
- 컨슈머 그룹에서 탈락하지 않기 위한 Heartbeat 기준 (session.timeout.ms / heartbeat.interval.ms)
- 초반 리밸런싱 대기 시간 (group.initial.rebalance.delay.ms)
- 파티션/컨슈머 어느 한 쪽의 멤버 수가 과하게 많진 않은지 확인하기
- 근본적으로는 이벤트 처리 로직 최적화하기
이슈 5. 처리 지연으로 인한 컨슈머 그룹 탈락
문제 상황
브로커는 컨슈머들이 메시지를 잘 처리하는지 주기적으로 감시한다. 만일 어리버리한 컨슈머가 있으면 컨슈머 그룹에서 탈락시킨다.
내부 비즈니스 처리 이슈로 인해 지연이 발생한 서버들이 컨슈머 그룹에서 하나 둘씩 탈락하기 시작했고, 이로 인해 토픽의 메시지를 소비하지 못하고 계속해서 쌓이게 되는 문제가 발생하였다.
해결 방안
컨슈머의 처리를 잘 모니터링하고 관리해야한다!
컨슈머 그룹 탈락과 관련하여 대표적으로 2가지 옵션을 확인할 수 있다.
- 폴링 주기 (max.poll.interval.ms)
- 폴링 시 메시지 양 (max.poll.records)
즉 N초 안에 M개의 레코드를 처리하길 기대하는 브로커의 기대를 충족시켜야한다.
처리 속도와 Consumer Group Leave 로그 또한 적극적으로 모니터링 해야한다.
이슈 6. 디스크 부족
카프카는 디스크 기반으로 동작한다. 디스크 알람이 발생하여 확인해보니 예상보다 많은 불필요한 데이터가 리소스를 차지하고 있었다.
문제 상황
카프가 스트림즈에는 상태저장소라는 db 개념이 존재한다. 이 데이터들은 각 스트림 프로세서들의 로컬에 분산 저장된다. 때문에 특정 서버가 갑자기 이슈가 다운되면 데이터 유실이 발생할 수 있기 때문에, 브로커에 changelog topic이라는 백업개념의 내부 토픽이 생성된다. 그리고 이 내부토픽은 시스템에서 자동으로 생성해주기 때문에 우리가 잘 신경쓰지 않았었다. 이 부분에 불필요한 과거 데이터가 쌓이고 있었고, 이로 인해 디스크를 잡아먹고 있었다.
해결 방안
다음 두 가지 옵션을 통해 불필요한 과거 데이터를 삭제했고, 이로 인해 디스크 사용량을 절반 가까이 줄일 수 있었다.
cleanup.policy
- delete : 데이터 유지(retention) 기간/크기에 따라
- compact : 키별로 최신의 값만 유지
상태저장소를 쓰면서 추가로 느낀 점
1. 분산 처리 이점을 누려야한다!
우리는 처음에 스트림 프로세싱을 한 뒤 그 결과를 redis에 넣었다. 처음에는 괜찮았지만 redis 데이터와 접근하는 곳이 증가하며 한계에 부딪혔다. 상태 저장소 데이터는 각 스트림 프로세서 로컬에 저장되기 때문에 접근도 빠르고 부하도 분산된다.
2. 하지만 반대로 상태저장소를 고집할 필요도 없다.
데이터가 브로커나 로컬 인스턴스의 디스크, 혹은 인메모리에 저장되는데, 이게 날아갈 경우 문제가 된다. 이를 changelog topic이나 레플리케이션 복제가 보완해주긴 하지만, 디버깅 난이도가 상대적으로 어려울 뿐만 아니라, mysql이나 redis만큼의 신뢰가 있지 않다. 그리고 오프셋 리셋 방식으로 복구가 가능한 데이터여야 한다. 따라서 우리는 상태저장소는 원장 데이터보단 임시 데이터를 보관하기에 적합하다고 판단했다.
비슷한 맥락에서 배치 처리로 충분한 걸 굳이 스트림 처리를 고집할 필요도 없다.
추가로 느낀 점
1. 리파티셔닝을 자제하자.
map()과 같은 메서드를 호출할 때 키를 변경할 수 있다. 키가 바뀌면 키를 따라가는 파티션도 이동한다. 이때 대규모로 데이터가 이동하면서 네트워크, 디스크 IO 부하가 발생할 수 있다. 따라서 가급적 키 변경 연산(map, transform, flatMap, groupBy)보다는 mapValues, transformValues, flatMapValues, groupByKey의 사용을 권장한다.
2. 스트림 처리 중에는 가급적 외부 API/DB 호출을 하지 말자.
이를 위해서, 스트림 프로세서에 도달하기 전에 미리 이벤트 페이로드를 풍부하게 구성한다. 또는 스트림 처리 내부에서 이들이 제공하는 조인 기능을 활용한다.
3. kafka 이외의 모든 키 기반 동작이 그렇듯이, 스트림즈에서도 특정 파티션에 몰리지 않도록 키 관리를 유의하자.
모니터링 및 관리
모니터링
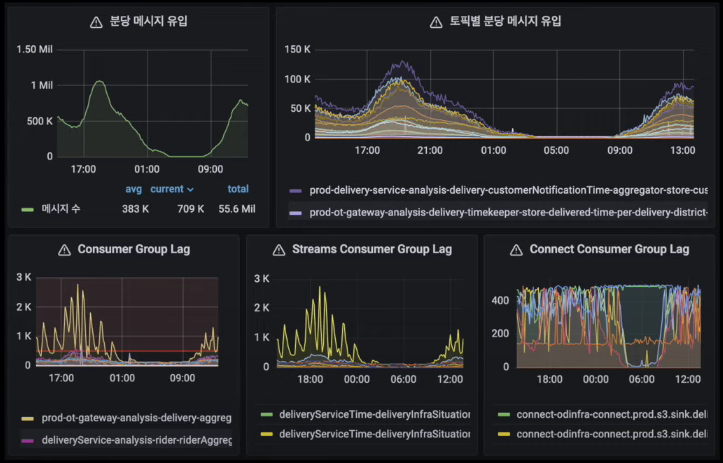
Burrow를 사용하여 모니터링 하고 있다.

사내 시스템들은 대부분 java spring 환경이기 때문에, jmx를 통한 지표도 모니터링하고 있다.
spring은 micrometer를 통해 쉽게 수집할 수 있다.
대표적으로 eventstore request latency와 consumer commit latency 지표를 모니터링하고 있다.

스트림 프로세서에는 7가지 상태가 있다. (실행 중, 중지, 리밸런싱, 에러 등)
스프링 카프카는 이에 대한 인터페이스를 제공한다. 프로메테우스를 통해 주기적으로 이를 수집하고 그라파나로 이를 노출해서 알림을 받고 있다. 이를 통해 우리는 에러나 리밸런싱 상태에 빠진 스트림 프로세서를 인지할 수 있다.
관리
1. 스트림 프로세서 상태 관리
상태에 대한 어드민을 구성해서 알람이 발생하면 문제가 되는 스트림 프로세서를 재시작하는 조치를 하고 있다.
2. CMAK
카프카 매니저를 통해 토픽에 대한 설정을 주로 하고 있다.
3. 스트림즈 리셋 기능
스트림 처리 환경에서는 배치 처리와 다르게 한 번에 결과가 나오는 게 아니라 이벤트가 넘어올 때마다 순차적으로 처리해서 누적하면서 결과를 만들어간다. 때문에 이슈 상황에서도 복구를 위해서 이벤트를 순차적으로 다시 소비할 필요가 있다.
우리는 카프가에 내장된 “Kafka-streams-application-reset-tool” 툴을 이용하여 컨슈머의 오프셋을 되돌려서 토픽의 과거 데이터부터 차례대로 다시 재소비할 수 있다. 물론 이 때 상태저장소나 내부 토픽은 리셋된다.
그리고 이를 매번 터미널에 들어가서 스크립트를 실행하기는 번거롭고 실수가 발생할 수도 있기 때문에 스트림즈 리셋을 jenkins로 wrapping해서 쓰고 있다.
새롭게 알게된 점 / 느낀 점
- 배민 서비스에서 배달과 라이더의 현황을 집계하기 위해 뒷단에서 어떤 일들이 실시간으로 이뤄지고 있는지 알 수 있었다.
- 배치 처리에 한계가 느껴진다면 스트림 처리를 사용해보는 것을 고려해봐야한다.
- 스트림 처리 도구에는 스파크(Spark), 스톰(Storm), 카프카 스트림즈(Kafka Streams), 플링크(Flink) 등이 있다는 걸 알게 되었다.
- 카프카 스트림즈에는 여러 개의 스트림 프로세서가 있고, 각 스트림 프로세서에는 상태 저장소가 1개씩 할당되어 있는 듯하다.
- 스트림 프로세서 각각은 카프카의 컨슈머로서 동작하며, 구독한 파티션에서 실시간으로 데이터를 받아온다.
- 카프카 및 카프카 스트림즈를 사용하며 발생할 수 있는 다양한 이슈 상황에 대해 알 수 있었다. 향후에 카프카 써보다가 문제가 발생하면 참고할 수 있을 듯하다.
- 카프카 운영 시 옵션 값을 잘 설정하는 것이 중요하다는 것을 알 수 있었다.
'IT 일상 > 세미나 및 컨퍼런스' 카테고리의 다른 글
| [우아콘2023] 대용량 트래픽을 받는 모놀리식 서비스에 Woowa하게 RPC 적용하기 (0) | 2024.02.06 |
|---|---|
| [우아콘2023] Kafka를 활용한 이벤트 기반 아키텍처 구축 (0) | 2024.01.21 |
| [우아콘2023] 대규모 트랜잭션을 처리하는 배민 주문시스템 규모에 따른 진화 (1) | 2024.01.17 |
| AWS Summit Korea 2022 (22.05.10 - 22.05.11) (0) | 2022.05.11 |
| 디지털 대전환 엑스포 (21.11.27) (0) | 2021.12.15 |