[우아콘2023] Kafka를 활용한 이벤트 기반 아키텍처 구축
※ 영상을 보며 아래 노션 페이지에 내용을 정리하였고, 포스트에는 노션을 한 번 더 요약한 내용을 담았습니다.
[우아콘2023] Kafka를 활용한 이벤트 기반 아키텍처 구축 | Notion
https://www.youtube.com/watch?v=DY3sUeGu74M
jn307742.notion.site
내용 요약
이벤트 기반 아키텍처를 왜?
'배달' 시스템이 점점 커짐에 따라 '알림', '배달시간', '통계', '쿠폰' 등 부가적인 기능이 필요해졌다. 이 모든 기능들을 하나의 배달 시스템에서 관리하기에는 복잡도가 너무 커져 시스템을 모두 분리하기로 하였다.
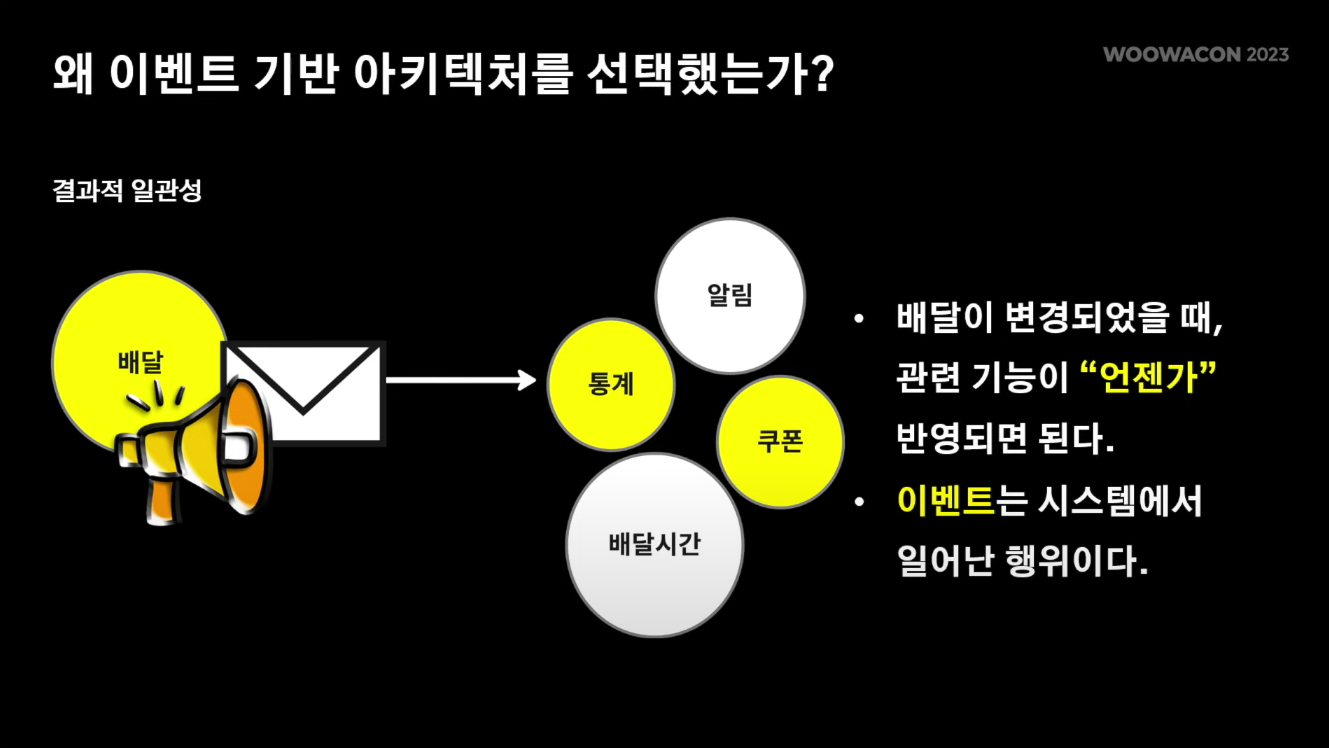
알림, 배달시간 등의 기능들은 배달 기능과 강한 일관성을 필요로하지 않는다. 즉, 배달이 변경되었을 때 다른 관련 기능들이 '동시에' 반영될 필요가 없다.
따라서 비동기성이라는 특징을 갖는 이벤트 기반 아키텍처를 도입하여 관련 다른 기능들을 관리하기로 결정하였다.
이벤트의 구성요소
마틴 파울러(Martin Fowler)는 도메인 이벤트를 "도메인에 영향을 주는 관심정보"라고 정의하였다. 또한 도메인 이벤트를 '대상', '발생한 시각', '행동' 이 세 가지 정보로 표현하였다.
이를 참고하여 배민에서는 배달 시스템의 특성에 맞게 이벤트의 구성 요소를 '대상', '행동', '정보', '시간'으로 정의하였다.
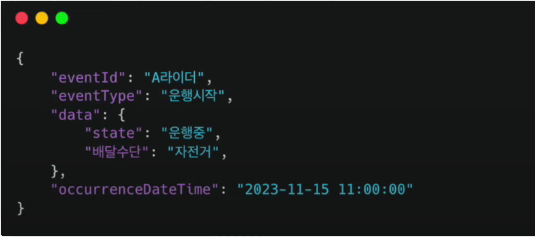
대상 (eventId)
- 어떤 배달이 변경되었는지
- 대상의 식별자 정보를 제공한다.
- 배달이 A라이더에게 11시에 배차되었다.
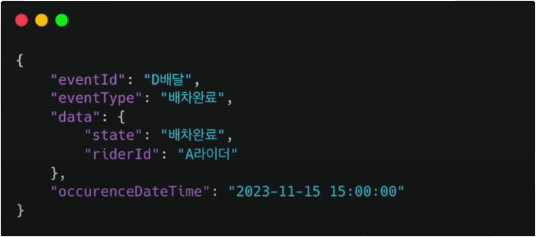
행동 (eventType)
- 상태 변경뿐 아니라 도메인에 일어난 모든 사건
- 이미 벌어진 사건이므로 과거형으로 표현
- 배달이 A라이더에게 11시에 배차되었다.
정보 (data)
- 행위와 관련된 값들
- 필요하다면 행위 외의 값도 추가 가능
- 배달이 A라이더에게 11시에 배차되었다.
시간 (occurenceDataTime)
- 행위가 발생한 시간
- 배달이 A라이더에게 11시에 배차되었다.
이 4가지 요소를 통해 도메인의 이벤트를 다양하게 표현할 수 있게 되었다.
이렇게 했을 때 좋았던 점
- 확장 용이 : 요구사항이 추가되더라도 배달 시스템 복잡도에 영향이 없다.
- 소비처 결합도 감소 : 소비처가 배달 상세정보를 api등을 통해서 다시 조회하지 않아도 됨
- 데이터 분석 : 도메인 히스토리 파악에 용이하여 분석 정보로 활용 가능했다.
주의할 점
- 소비처 요구사항에 대한 이벤트 데이터의 무분별한 추가 주의 (소비처 비즈니스 결합도가 올라갈 수 있기 때문)
- 이벤트의 순서가 꼬이지 않게 주의
이벤트 파이프라인
이벤트 브로커 : Kafka
이벤트를 발행하려면 이벤트 브로커가 필요하다.
사내에서는 주로 sns, sqs 또는 kafka를 사용하고 있었고, 둘 중 무엇을 이벤트 브로커로 사용할지 고민한 끝에 다음 4가지 이유로 kafka를 선택했다.
1. 순서 보장
kafka는 토픽의 파티션을 통해 key별로 순서를 보장한다.
2. 고성능, 고가용성
kafka는 파티션 증설을 통한 처리량 증대, 메시지 배치 발행, 페이지 캐시 등을 이용하여 고성능을 제공해주고 있다.
또한 브로커를 클러스터로 관리해줌으로써 한 대의 브로커에 이슈가 생겨도 다른 브로커에서 파티션을 처리하게 함으로써 고가용성을 보장해주고 있다.
3. 통합 도구
kafka 생태계에서는 kafka streams, kafka connect 등 다양한 통합 도구(EcoSystem)를 제공하고 있다.
4. 전담팀 지원
우아한형제들 사내에서는 카프카를 전담으로 관리해주는 카프카 팀이 있었다. 해당 팀에서는 브로커를 관리해줄 뿐만 아니라 모니터링 시스템 등을 제공해줬다. 따라서 서비스 팀에서는 카프카를 안정적으로 사용할 수 있었다.
kafka 도입 후 발생한 문제점
kafka가 고가용성을 보장해준다고는 했지만 브로커의 ebs 볼륨 이슈, 주키퍼와의 통신 이슈, 네트워크 이슈 등으로 이벤트 순단이 발생했다. 이로 인해 이벤트 발행이 실패하거나 재시도 처리를 하면서 이벤트의 순서가 변경되었다. 이는 결국 도메인의 상태와 이벤트 발행 결과가 불일치하게 되었고, 이는 시스템의 장애로 확산되었다.
이러한 문제를 해결하기 위해 트랜잭셔널 아웃박스 패턴을 사용하였다.
Transactional Outbox Pattern
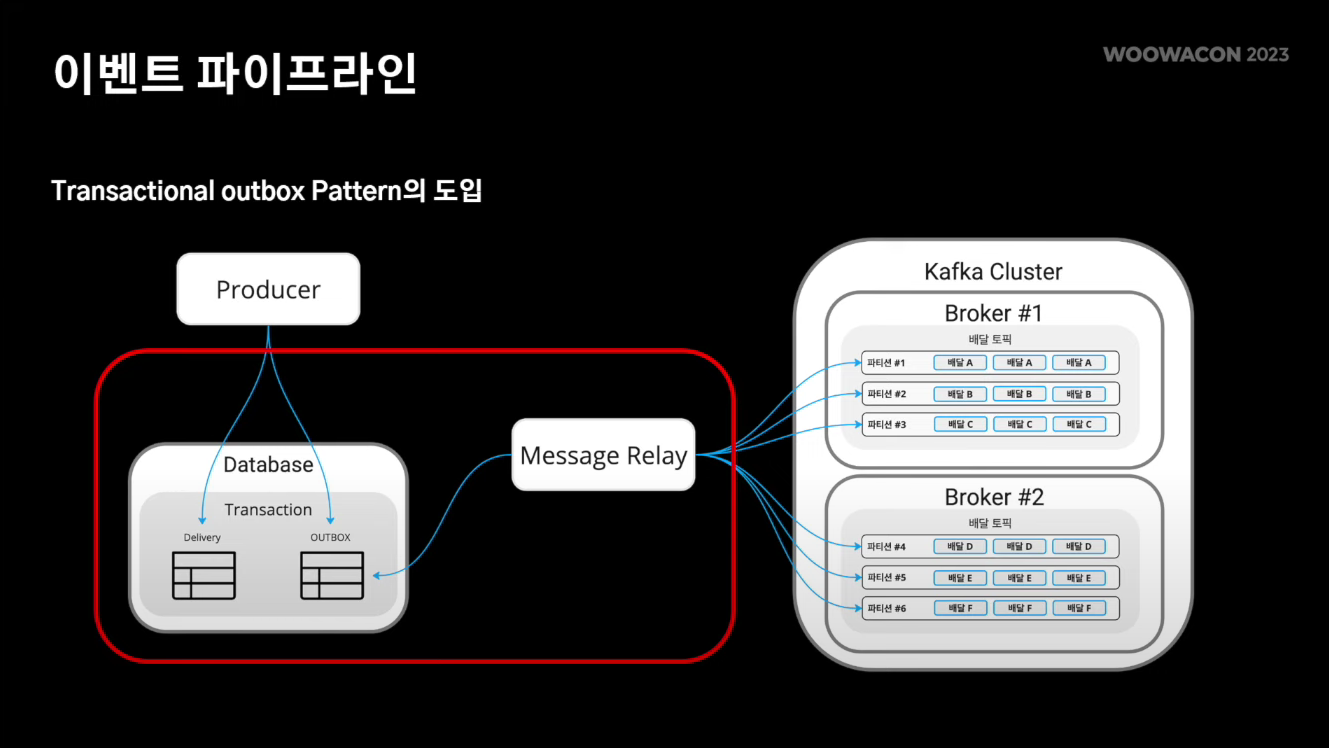
트랜잭셔널 아웃박스 패턴은 이벤트 기반 아키텍처에서 사용되는 패턴 중 하나로, 동작 순서는 다음과 같다.
- 발행해야할 이벤트를 도메인 처리 트랜잭션과 묶어 아웃박스 테이블에 저장한다. 이를 통해 도메인의 상태와 발행해야 할 이벤트 간의 일관성을 보장해줄 수 있다.
- 이후 메시지 릴레이가 아웃박스 테이블에 저장된 이벤트를 순서대로 읽어 발행한다. 이를 통해 이벤트의 순서와 발행을 보장해줄 수 있다.
메시지 릴레이 : Debezium
메시지 릴레이(Message Relay)로 오픈소스인 디비지움(Debezium)을 선택하였다.
디비지움은 데이터베이스 시스템에서 발생하는 변경사항을 감지하고, 타 시스템에 전송해주는 오픈소스 플랫폼이다.
디비지움은 메시지 릴레이로서 다음 3가지의 장점이 있었다.
1. 저비용 : 설정을 통해 커넥트 등록/실행 및 모니터링 제공
디비지움은 kafka connect로 제공되고 있다. 이미 사내에서는 kafka 모니터링 체계가 구축되어 있었고, 거기에 connect 지표만 추가하면 됐다.
2. 안정성 : binary log를 순서대로 읽어 이벤트의 순서를 보장
kafka 순단이 발생하더라도 발행이 실패한 offset부터 읽어 재시도를 통해 발행을 보장한다.
3. 처리량 : outbox 테이블 파티셔닝을 통한 처리량 증대
일반적으로 Kafka Connect를 쓰면 task 수를 조절하여 처리량을 증가시킬 수 있다. 하지만 MySQL Debezium Connect는 task 수를 1개로 고정해야한다. (바이너리 로그를 순서대로 읽기 위해서인 듯 하다.)
이를 해결하기 위해 outbox 테이블 파티셔닝을 진행하였다.
outbox 테이블을 n개 만들고, producer가 이벤트 키를 기반으로 이벤트를 파티셔닝하여 적절한 outbox 테이블에 저장하였다. 그리고 각각의 outbox 테이블에 debezium connect를 붙여 이벤트를 발행함으로써 처리량을 증대시킬 수 있었다.
💡 Kafka Connect
- kafka를 사용하여 외부 시스템과 데이터를 주고 받기 위한 오픈소스 프레임워크
- kafka connect를 사용하여 kafka와 다른 데이터 시스템 간에 데이터를 스트리밍하고 kafka 안팎으로 대규모 데이터 셋을 이동시켜주는 커넥터를 빠르게 생성할 수 있다.
💡 디비지움 (Debezium)
- Kafka Connect 기반의 플러그인
- CDC(Changed Data Capture, 변경된 내용을 골라내는 기술)를 사용하여 데이터베이스의 변경사항을 수집한다.
- Debezium이 데이터베이스 로우 레벨의 변경 사항을 캡쳐하면, 애플리케이션은 이를 보고 처리할 수 있다.
- Debezium은 MongoDB, MySQL, SQL Server, Oracle 등 다양한 커넥터를 제공한다.
최종 아키텍처
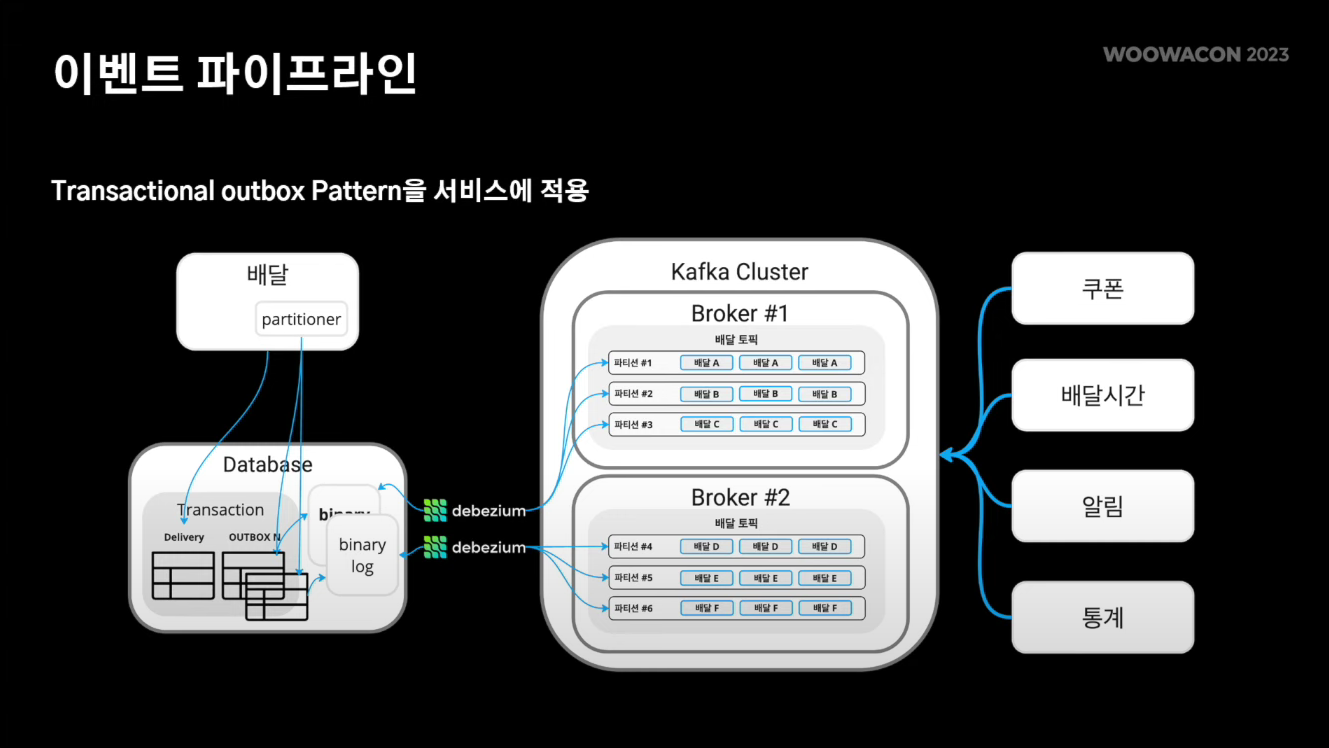
이벤트 활용 사례
1. CQRS 적용
향후에 CQRS를 적용할 때 이벤트 스트림을 기반으로 쿼리 모델을 구축했다. (CQRS 자체에 대한 설명은 생략)
2. 데이터 분석 환경 구축
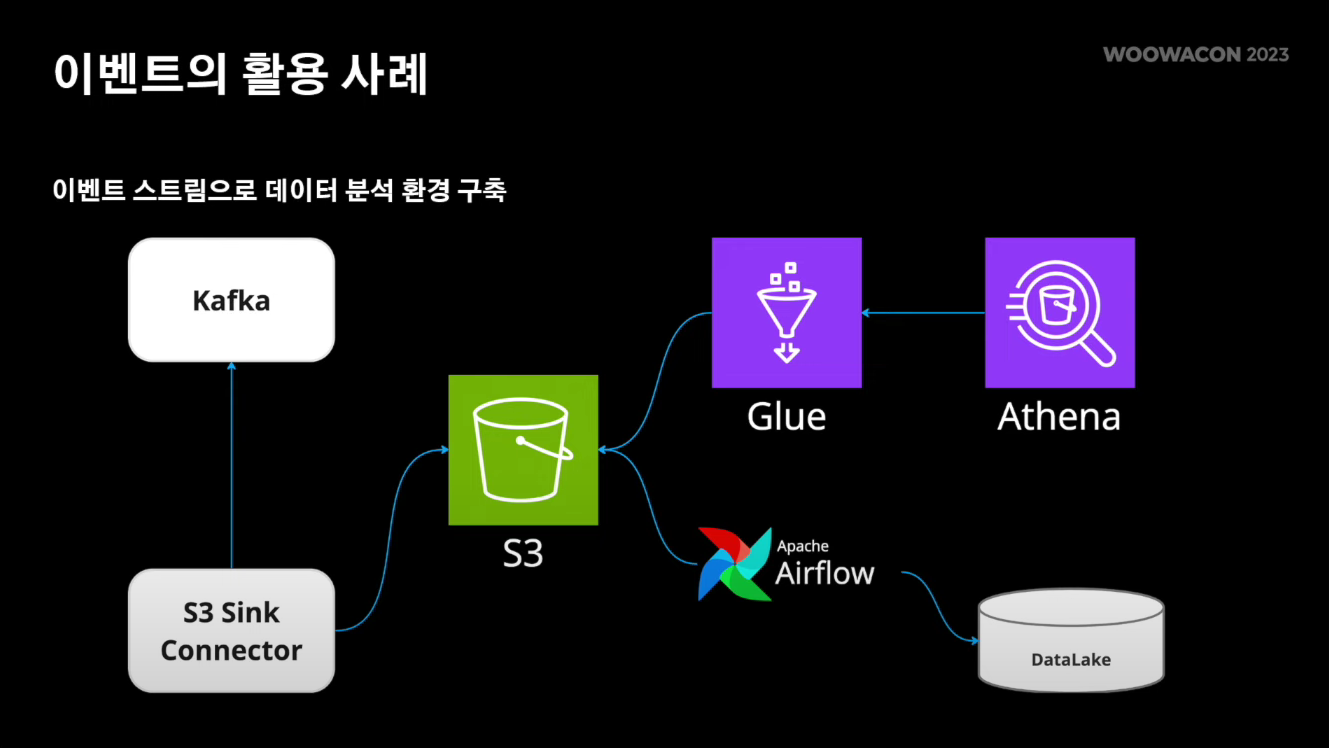
Kafka에 저장돼 있는 이벤트 스트림을 s3 sink connector를 통해서 s3에 저장했다.
이후에 aws에서 제공해주는 glue와 athena를 활용하여 데이터를 분석할 수 있는 환경을 구축했다.
또한 배달 데이터는 다른 팀에서도 많이 모니터링하고 있기 때문에, 해당 데이터를 전사 data lake에 연동함으로써 다른 팀도 배달 데이터를 분석할 수 있게 제공해 주었다.
3. 스트림즈 애플리케이션 구현
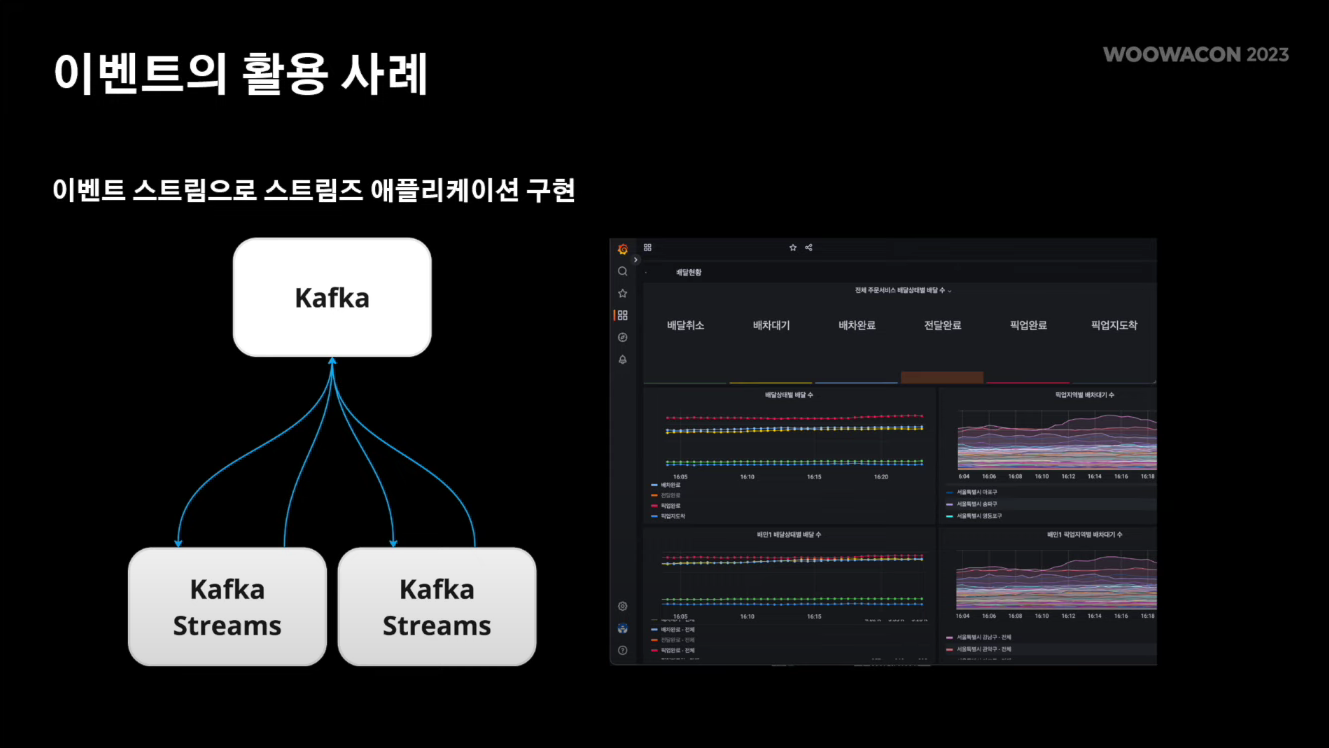
Kafka Streams를 활용하여 특정 지역, 특정 시각의 배달과 라이더 수를 집계하는 이벤트 스트림 기반의 스트림즈 애플리케이션을 구현했다. Kafka Streams에서는 스트림간의 조인, 상태 저장소 기능을 제공하고 있어서 다양한 집계 니즈를 해결할 수 있었다.
새롭게 알게 된 점 / 느낀 점
- MSA에서 MQ, 이벤트 기반 아키텍처, Transactional Outbox 패턴 이 3가지는 자주 같이 쓰이는 것 같다.
- Kafka Connect에 대해 알게 됐다. Kafka가 외부 시스템(특히 데이터베이스)와 통신할 때 필요한 프레임워크이다.
- Debezium에 대해 알게 됐다. Kafka Connect의 플러그인 중 하나로, 디비지움을 사용하면 데이터베이스의 변경 사항을 캡쳐해서 애플리케이션에 알려줄 수 있다.
- Kafka Streams가 살짝 언급되어서 찾아보다가 스트림 및 스트림 프로세싱에 대해 간단하게 알게 되었다. '스트림 프로세싱'은 끝 없이 들어오는 데이터를 실시간으로 처리하는 것이다. '배치 프로세싱'과 대치되는 개념이다.
- SNS와 SQS가 살짝 언급되어서 찾아보았다. 둘 다 Amazon에서 제공되는 서비스로 비슷하지만 살짝 다르다. SNS는 pub/sub 시스템으로, topic을 통해 여러 소비자에게 동일한 메시지를 보내는 방식이다. SQS 는 큐잉 시스템으로, 큐의 각 메시지는 한 소비자에 의해서만 처리되는 방식이다.
- 예전에 MSA를 적용한 프로젝트를 진행한 적 있었는데, 그 때는 시스템 간 통신은 직접 api 통신을 하는 방법을 선택했었다. 하나의 시스템에서의 변화가 다른 시스템에 영향을 줄 때 이를 비동기적으로 처리해도 된다면, 직접 api 통신을 하는 것이 아니라 MQ를 이용한 이벤트 기반 아키텍쳐를 활용하는 것이 좋았을 것 같다.